Over mij

Wie ben ik?
Ik ben Nordin, een 22 jarige zelf aangeleerd programmeur met zo'n 2,5 á 3 jaar aan ervaring.
Over de laatste jaren heb ik CS50x afgemaakt, een paar kleine projectjes gebouwd en heb
ik mijn eerste grote project, Discount Checker gemaakt. Ik heb dit allemaal gedaan
in mijn vrije tijd terwijl ik part-time werkte, grotendeels als schoonmaker
Waarom ik begon met programmeren
Ik ben altijd al geïnteresseerd geweest in tech, maar ik had nooit de tijd genomen om me er in te verdiepen,
totdat ik ontslag nam van mijn baan als bedrijfsadministrateur. Ik voelde dat ik vast zat in dat werk en ik wilde iets vinden
waar ik voor altijd zou kunnen leren en groeien. Door die keuze ben ik gaan programmeren, waardoor ik een passie vond
waar ik niet eerder van afwist. In deze tijd ben ik gaan houden van systeem architectuur, het oplossen van complexe problemen,
het schrijven van goede, onderhoudbare code en het opbouwen van applicaties.
Mijn favoriete stack
Mijn favoriete stack is de backend. Ik hou er niet alleen van om het werkend te krijgen, maar vooral van het ontwerpen ervan:
nadenken over trade-offs, edge cases, mogelijke faalpunten en het schrijven van modulaire, goed gestructureerde code
die makkelijk te onderhouden en te updaten is. Zelfs in een stack die ik iets minder leuk vind, zoals de frontend,
hou ik kwaliteit als hoogste prioriteit. Ik wil dat de user experience soepel, prettig en duidelijk is.
Een goede backend verdient tenslotte ook een goede frontend.
Discount Checker
Discount Checker in een project dat ik oorspronkelijk had gemaakt voor mijn CS50x eindproject.
De eerste versie was heel simpel, kon alleen op localhost runnen en was meer een proof of concept.
Wat het nu is geworden, is een full-stack, productie kwaliteit project compleet door mij gemaakt.
Wat doet Discount Checker?
Het doel van Discount Checker is om alle producten die jij wilt van verschillende webshops
op één plek bij elkaar te brengen. Je hoeft niet meer 5 verschillende websites the checken om te zien
of een product in de aanbieding is, je kunt gewoon naar één website gaan en alles op één plek zien.
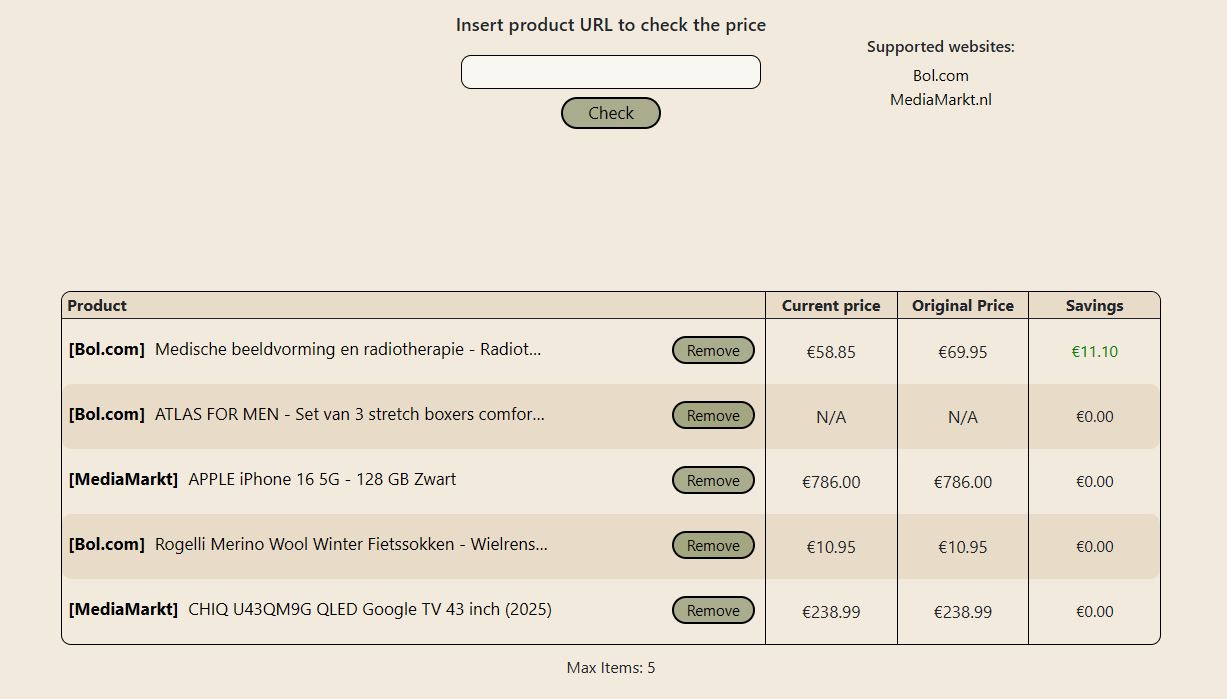
Wil je Discount Checker uitproberen?
Maak een account, log in, vul de tekstbox in met een product-URL van een ondersteunde webshop en klik op check!
Hoe is het gemaakt?
Discount Checker is een web applicatie gebouwd in Python met tools zoals Flask voor de backend, SQLAlchemy als ORM,
Celery/RedisMQ voor rate limiting en task scheduling. Het is gedeployed met Docker, nginx en waitress.
Het gebruikt een zelfgebouwde web scraping API in FastAPI,
met Playwright voor de headless browser, een rotating residential proxy tegen botdetectie en nginx + gunicorn voor de deployment.
Code
standaardisatie van URLs
Ik kwam er heel snel achter hoe complex het herscrapen van een product database kan zijn vanwege verschillen in gebruikersinput, maar ook
inconsistenties in URLs. Om dit tegen te gaan, standardiseer ik alle URLs en verwijder ik de trailing data voordat ze in de database komen.
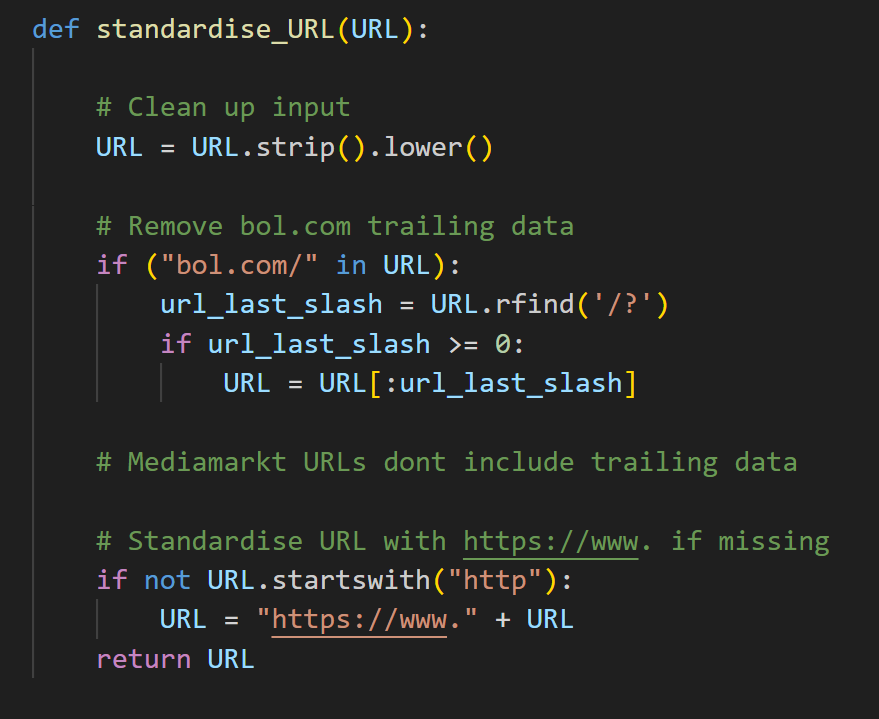
URL opschonen.
Bol.com URLs hebben een patroon van "/?" voor hun
trailing data.
Als dit patroon bestaat, gebruik ik de index van
"/?" om de trailing
data eraf te slicen.
Ik standardiseer al de URLs zodat mijn deduplicatie
logica
consistent blijft. Ik doe dit door "https://www."
toe te voegen
aan URLs die dit nog niet hebben.
Uitleg
Deze snippet is van functions.py in lijn 69
Duplicaten in de Database voorkomen
Er is een mogelijkheid dat meerdere gebruikers hetzelfde product in hun tabel willen hebben. Om hiermee om te gaan heb ik deduplicatie
logica toegevoegd, dit versnelt niet alleen de request tijd omdat het de data direct uit de database haalt,
maar het bespaart ook resources omdat de API niet geroept hoeft te worden.
The deduplicatie logica:
Is het requested product al in de products tabel van de database?
if it is:
Check of het product ook in de userProducts tabel bestaat voor de huidige userID
if it is:
Laat de gebruiker weten dat het product al in hun tabel zit en voeg het niet toe
else:
Voeg het product toe aan userProducts met de bestaande productID en userID
else:
Roep de API en voeg de product data toe aan de products en userProducts tabellen
Om de code te zien, kijk naar de "/add_product" route in: app.py in lijn 179
Data Flow
Gebruikers input
Web Server Backend Validatie
API Request
Celery Task Queue
API Response
Opslaan in Database
Front-end Table Display
Input in de vorm van een URL
Backend checkt of de URL van een ondersteunde
website is
Web server roept de request_API( ) Celery task
Request gaat de Queue in met een concurrency van 1
om de server niet te overbelasten
Web Server ontvangt de product data van de
API In de vorm van een dictionary
Product data wordt opgeslagen in de products en userProducts tabellen
Frontend krijgt de product data van de backend en toont het aan de gebruiker
Handelen van een lege product tabel
Ik vond dat de product tabel er niet goed uit zag wanneer hij leeg was, dus besloot ik een bericht toe te voegen als hij leeg is.
Deze snippet is van index.html in lijn 142
Deze functie checkt for een lege tabel op page load.
checkRows is een simpele functie die check voor de
hoeveelheid aan rijen in het tabel van de gebruiker.
Als de hoeveelheid aan rijen 0 is,
creert de emptyTableMessage( ) functie een nieuwe rij
voor het tabel en toont hij een simpel bericht met
instructies over hoe je een product kan toevoegen.
Wanneer een product verwijdert is, gebeurt hetzelfde process,
hij checkt voor de hoeveelheid aan rijen en als dat
0 is, voegt hij de "Empty Table Message" toe
Deze snippet is van main.js in lijn 165
Het handelen van real-time gebruikers input
Het alleen sturen van geldige URLs naar mijn API is heel belangrijk, niet alleen om crashes te voorkomen maar ook om onnodige kosten te besparen. Om dit te doen check ik heel simpel of de domein naam van een ondersteunde website in de requested URL zit, zo wel dan stuur ik hem naar de API, zo niet geef ik de gebruiker een duidelijk feedback bericht met de vraag voor een geldige URL.
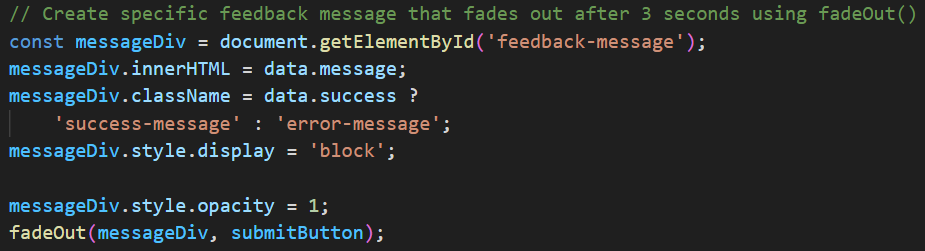
Deze snippet is van index.html in lijn 98
Persoonlijk geloof ik dat het heel belangrijk is om duidelijke feedback te geven aan gebruikers voor een goede user experience. Om dit te voorzien heb ik een feedback bericht systeem die gebruikers feedback geeft gebaseerd op de situatie.
Bijvoorbeeld tijdens een user request zet ik de "submit" button uit, laat ik een loading spinner zien en de text "Getting product data...". Nadat de request over is krijgen ze feedback of de request successvol was of niet en word de "submit" button weer aangezet.
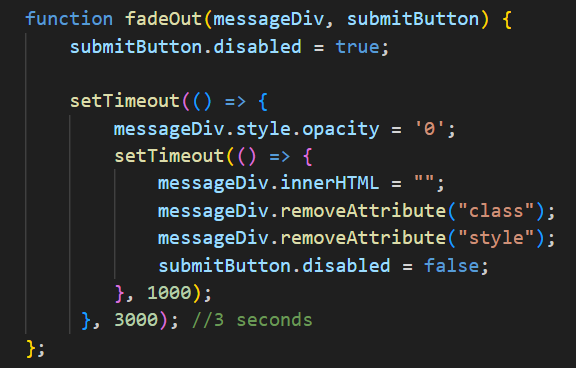
Deze snippet is van main.js in lijn 24
Nadat het feedback bericht op de frontend staat, wordt de fadeOut( ) functie geroepen
Deze functie neemt de div van het feedback bericht(messageDiv) en de
submit button(submitButton) als argumenten
Als deze functie geroepen is, zet hij meteen de submit button uit om spam misbruik te voorkomen, wacht hij 3 seconden door setTimeout, zet hij opacity naar 0 zodat het weg vaagt, wacht hij nog 1 seconden, verwijdert hij de content van de messageDiv en zet hij de button weer aan zodat de gebruiker hun volgende request kan maken.
Web Scrapen
Oorspronkelijk gebruikte ik BeautifulSoup4 voor de CS50x versie van Discount Checker. BS4 is heel goed voor statische content scrapen, maar ik liep heel snel tegen een probleem aan toen ik dit project ging verbeteren. Wanneer de cookies pop up verscheen, blokkeerde het de HTML van de pagina met een JS script. Om dit probleem op te lossen had ik wat onderzoek gedaan en kwam ik erachter wat een "headless browser" is, degene die ik vond waren Playwright en Selenium. Ik heb playwright gekozen omdat het moderner is, asynchronous is en het heeft geweldige documentatie.
Bol.com Scrapen
Bot detection
Bol.com heeft consistente en hele schone HTML, dit maakte het scrapen van de website in development heel makkelijk. Maar toen ik het op mijn VPS probeerde stopte het meteen met werken vanwege bot detectie, dit leidde naar een strijd tegen de bot detectie die 3 weken duurde waar ik verschillende browsers, verschillende browser argumenten, random pauzes om een gebruiker te imiteren en residential proxies heb geprobeerd.
Wat uiteindelijk werkte was een combinatie van deze technieken. Ik had een open source community gemaakte upgrade van Playwright gevonden die Patchright heette en deze hielp heel goed tegen bot detectie, maar dat was niet genoeg, wat uiteindelijk voor betrouwbaarheid zorgde, was een rotating residential proxy van Oxylabs. De combinatie van Patchright, browser argumenten, random pauzes en de proxies maakte de scraper heel stabiel en betrouwbaar.
Productdata verzamelen
Wanneer het neerkomt op het ophalen van de productdata is het heel makkelijk dankzij de schone en consistente HTML van Bol.com.

Deze snippet is van mainPlay.py in lijn 117

Bol.com prijzen
Bijvoorbeeld in deze code snippet, check ik of het "original price" element bestaat ("h-nowrap"), als deze niet bestaat dan betekent het dat het niet in de uitverkoop is en zet ik beide prijzen naar de standaard prijs die gevonden is. Maar, als de "original price" wel bestaat betekent het dat het product wel in de uitverkoop is en 2 prijs waarden heeft, de "original price" en de "current price" (zie foto voor voorbeeld). Om de "original price" te vinden, gebruik ik dezelfde class die ik eerder gebruikte om te checken of het element bestaat, ik pak dan de inner HTML, schoon ik de data op en return ik de data.
De cookies accept en taal selectie pop up die Bol.com gebruikt krijgt de scraper niet altijd te zien omdat de scraper session data opslaat. Dit maakt de scraper een klein beetje sneller omdat hij niet hoeft te wachten op de pop up en niet op de knoppen hoeft te klikken. Maar, als de scraper een error krijgt verwijdert hij altijd de session data om veilig te zijn.
Mediamarkt Scrapen
Mediamarkt scrapen was compleet anders. De uitdaging was niet de bot detectie, maar het scrapen van de content vanwege de HTML van Mediamarkt.
Ik gebruik dezelfde anti bot detectie techniek die ik voor Bol.com gebruik en dat werkt perfect. Ik kwam er alleen heel snel achter hoe slordig de HTML van Mediamarkt is, ze gebruiken willekeurige class namen die geen betekenis hebben, vaak veranderen en soms meer dan 10 keer gebruikt wordt op een pagina, hierdoor zijn deze classes niet goed om te gebruiken voor een stabiele scraper.
Mijn scraper bleef telkens kapot gaan door deze class namen, hierdoor begon ik met zoeken naar een betere strategie. Na een beetje zoeken en testen vond ik de "data-test" attribuut, de waarde van "data-test" wordt gebruikt in de parent element van de prijs element, veranderd nooit en wordt slechts 1 keer per pagina gebruikt wat het een perfecte attribuut maakt om mee te scrapen
De "Original Price" pakken
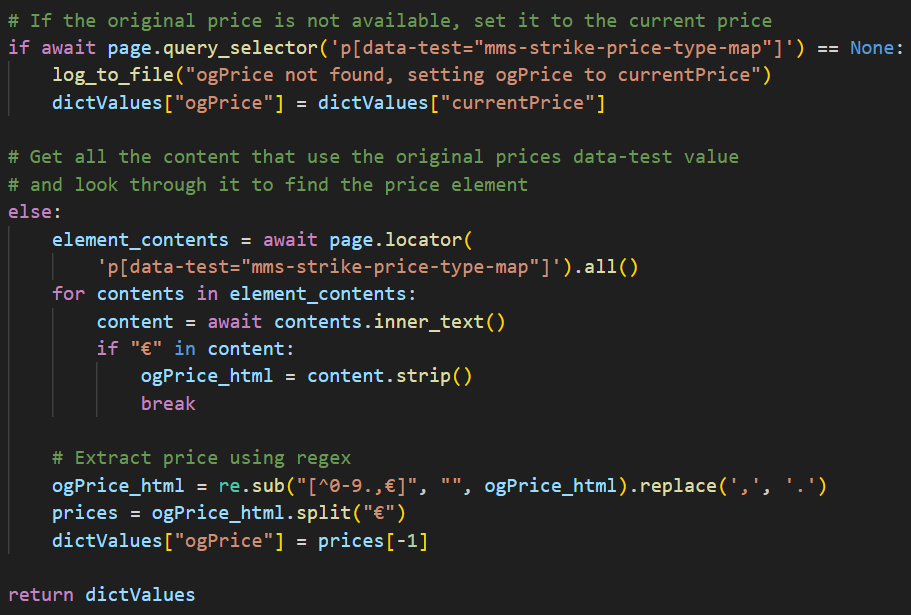
Deze snippet is van mainPlay.py in lijn 465
Dit voorbeeld laat zien hoe ik de "Original Price" pak, zoals je kan zien is het veel anders dan bij Bol.com. Het eerste gedeelte is hetzelfde, ik check of het "Original Price" element bestaat, zo niet dan zet ik hem naar de waarde van "Current Price".
Om de content van de "Original Price" element te krijgen moet ik eerst al de content van parent element krijgen met de data-test waarde. Ik gebruik een simpele loop om door alle content te zoeken voor een element die "€" in de HTML heeft, zodra ik die gevonden heb strip ik de whitespace en sla ik hem op in de ogPrice_html variable.
Wanneer de prijs gevonden is, moet hij schoongemaakt worden voordat hij naar mijn Flask app gestuurd wordt, om dit te doen gebruik ik regex. De split method wordt gebruikt omdat het p element met de data-test waarde de prijs 2 keer geeft, dus split ik de content en pak ik de laatste index in de lijst omdat deze correct geformat is.
Bijvoorbeeld, een product met de "Original Price" van "1099,–", geeft mij de waarde "€1099.€1099.00". Als ik deze waarde split, en de -1 index van pak, hou ik de waarde "1099.00" over die perfect is voor mijn Flask app.
Systeem
Separation of concerns tussen Flask app en API
Mijn project gebruikt 2 servers, beide servers zijn shared VPS instances. De server die mijn Flask app host is heel licht en heeft maar 2 vCPU cores vanwege de lage resource vereisten. De andere server wordt puur gebruikt voor de API en heeft 6 vCPU cores, dit is het minimale wat nodig is om een user request en een scheduled request tegelijkertijd te behandelen.
Ik hou de Flask app en API los van elkaar omdat dit resource management makkelijker maakt, beide environments makkelijker zijn om te onderhouden en het zorgt voor minder dependencies. Ze los van elkaar houden maakt ook debuggen makkelijker en ze kunnen elkaar niet vertragen.
Dual API Setup
Toen ik de webscraper API net had gebouwd was er maar één request type, user requests, dit werkte perfect op een singulaire API. Wanneer ik de scheduled rescrape had geïmplementeerd en een scheduled request stuurde naar deze singulaire API terwijl er al een user requests behandeld werd kwam ik meteen een probleem tegen, ik kreeg de error 'no browser instance'.
Na wat onderzoek en testen kwam ik erachter dat omdat de API al bezig was met een request, kon hij niet nog een browser instance opstarten. Om dit probleem op te lossen heb ik een identieke kopie gemaakt van de API en deze parallel gezet van de eerste API, deze APIs heb ik user_scraper en scheduled_scraper genoemd. Door deze dual API setup worden user requests en scheduled requests op dezelfde server behandeld, maar op verschillende APIs waardoor ze elkaar niet kunnen storen.
Sinds het designed van dit systeem heb ik geleerd wat browser pools zijn in Playwright, maar ik geloof nogsteeds dat deze dual API setup heel veel voordelen heeft. De separation of concerns blijft altijd fijn en ik hou meer controle over de
individuele APIs. Al zou ik browser pools implementeren kan ik meer controle hebben over hoeveel browser instances elke API kan hebben.
Bijvoorbeeld, de scheduled rescrape hoeft niet super snel te gaan omdat gebruikers niet zien dat hij runned. Dus met een grote user base kan ik de user_scraper API 5 browsers geven en de scheduled_scraper 3 browsers, deze controle
zou niet zo soepel zijn als ik alles op 1 API zou behandelen.
User request vs Scheduled Request
Beide request types worden anders behandeld. User requests zijn heel onvoorspelbaar, om hiermee om te gaan valideer en schoon ik de user input op (zoals uitgelegd in de Code sectie), de gebruiker verwacht feedback dus de Flask backend moet errors opvangen en daarop reageren. Scheduled requests zijn een stuk anders, vanaf het begin is de data al schoon en direct uit de database dus ik hoef niks te doen voor de requests, maar mijn scheduled rescrape systeem heeft "retry logic".
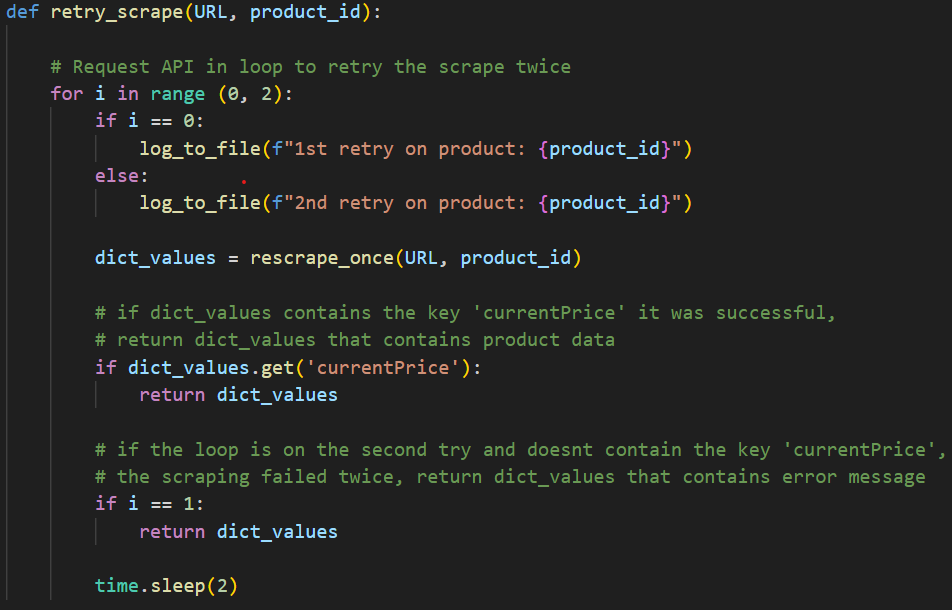
Deze snippet is van functions.py in lijn 145
Deze functie wordt geroepen wanneer de eerste rescrape faalt, wat leidt tot nog 2 pogingen voordat hij het logged, de error returned en het product overslaat.
Wanneer ik dit zie gebeuren in de logs, scrape ik het product altijd handmatig om te kijken wat er fout was gegaan, hierdoor heb ik best veel edge cases gevonden zoals onbeschikbare producten herkennen.
2025-08-26 03:03:06 - INFO - User ID: None - Requesting rescrape of product: 32
2025-08-26 03:03:22 - ERROR - User ID: None - Requested rescrape failed, retrying: {'error': 'Failed to scrape product data/alter product data', 'details': 'Page.wait_for_selector: Timeout 10000ms exceeded.\nCall log:\n - waiting for locator(".bPkjPs") to be visible\n'}
2025-08-26 03:03:22 - INFO - User ID: None - 1st retry on product: 32
2025-08-26 03:03:22 - INFO - User ID: None - Requesting rescrape of product: 32
2025-08-26 03:03:39 - INFO - User ID: None - Requested product successfully rescraped: {'name': 'MSI MAG 271QPX QD-OLED E2 - 27 inch - 2560 x 1440 (Quad HD) - 0.03 ms - 240 Hz', 'currentPrice': '559.00', 'ogPrice': '699.00'}
Deze snippet is direct uit mijn logs, de rescrape was gefaald omdat hij te lang moest wachten voordat class '.bPkjPs' zichtbaar was, deze class gebruik ik om te zien of de pagina geladen is omdat deze class 10+ keer gebruikt wordt op elke Mediamarkt product pagina. Hierdoor kan ik er vanuit gaan dat de pagina er te lang over duurde om te laden waardoor mijn scrapen een timeout error returnde, en op de eerstvolgende poging returnde hij successvol de product data wat betekent dat het 100% een connectie error was en geen code error.
API in actie
Deze video laat mijn API in actie zien met een handmatig geactiveerde rescrape. Het linker venster heeft een "Test" button waarmee ik de rescrape handmatig activeer, dit zorgt ervar dat de pagina befriest, maar in deployment gebeurt dit niet omdat het een scheduled task is die in de achtergrond runned.
Het venster rechtsbovenin is de htop(systeem monitor) van mijn webscraper API server die laat zien dat de API in gebruik is en daaronder zie je de logs van de rescrape in actie.
userProducts dagelijks rescrapen en alle andere producten wekelijks om kosten te besparen
Wat ik moet rescrapen en wanneer was een moeilijke keuze om te maken. Ik wou heel graag verse data, maar ik wou ook niet honderden per maand uitgeven aan proxies, dus een balans vinden was heel belangrijk.
Omdat webshops hun prijs data niet elke 30 minutes aanpassen, is één keer per dag checken genoeg en de enige data die up to date moet zijn is de data die gebruikers zien. Dus mijn oplossing is om de data die gebruikers zien op een dagelijkse basis vers te houden en alle andere data op een wekelijkse basis.
Mijn database heeft 2 product tabellen, products en userProducts, zoals de namen al zeggen is products een tabel voor alle producten en userProdcuts een tabel die userID(van de users tabel)
en productID(van de products tabel) verbind.
De products tabel wordt elke week om 03:00 CEST op dinsdag gerescraped om wekelijkse versheid te behouden in de hele database,
en omdat ik voor de toekomst een paar ideeën heb zoals de laagste prijs ooit gezien bijhouden of prijs grafieken voor gebruikers maken.
De userProdcuts tabel wordt elke dag om 03:00 CEST gescraped behalve op dinsdag want dan is de wekelijkse. Dit zorgt ervoor dat de data die gebruikers zien
heel vers is en alle andere data redelijk vers is terwijl ik de kosten op een minimum hou.
Database Structuur
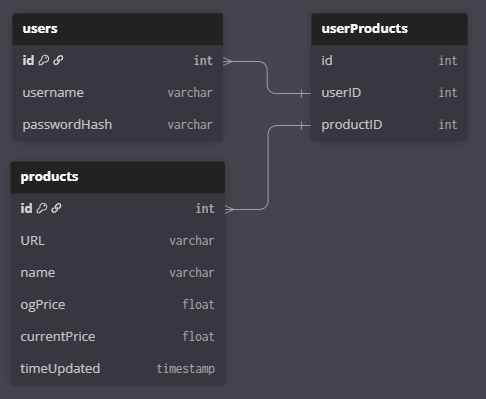
The database bestaat uit 3 tabellen: users, products en userProducts. userProducts is een junction tabel die gebruikers linkt aan de producten die ze willen volgen doormiddel
van de userID en de productID.
Het design zorgt ervoor dat de database simpel blijft maar ook meerder gebruikers de mogelijkheid geeft om hetzelfde product te volgen, dit bespaart opslag ruimte maar ook API gebruik.